
微软新作,ImageBERT虽好,千万级数据集才是亮点
2020-02-05 15:39 作者:
迎战疫情,艾锑无限用爱与您同行
为中国中小企业提供免费IT外包服务

这次的肺炎疫情对中国的中小企业将会是沉重的打击,据钉钉和微信两个办公平台数据统计现有2亿左右的人在家远程办公,那么对于中小企业的员工来说不懂IT技术将会让他们面临的最大挑战和困难。
电脑不亮了怎么办?系统蓝屏如何处理?办公室的电脑在家如何连接?网络应该如何设置?VPN如何搭建?数据如何对接?服务器如何登录?数据安全如何保证?数据如何存储?视频会议如何搭建?业务系统如何开启等等一系列的问题,都会困扰着并非技术出身的您。

好消息是当您看到这篇文章的时候,就不用再为上述的问题而苦恼,您只需拨打艾锑无限的全国免费热线电话:400 650 7820,就会有我们的远程工程师为您解决遇到的问题,他们可以远程帮您处理遇到的一些IT技术难题。
如遇到免费热线占线,您还可以拨打我们的24小时值班经理电话:15601064618或技术经理的电话:13041036957,我们会在第一时间接听您的来电,为您提供适合的解决方案,让您无论在家还是在企业都能无忧办公。
那艾锑无限具体能为您的企业提供哪些服务呢?

第一版块是保障性IT外包服务:如电脑设备运维,办公设备运维,网络设备运维,服务器运维等综合性企业IT设备运维服务。
第二版块是功能性互联网外包服务:如网站开发外包,小程序开发外包,APP开发外包,电商平台开发外包,业务系统的开发外包和后期的运维外包服务。
第三版块是增值性云服务外包:如企业邮箱上云,企业网站上云,企业存储上云,企业APP小程序上云,企业业务系统上云,阿里云产品等后续的云运维外包服务。
您要了解更多服务也可以登录艾锑无限的官网:www.bjitwx.com查看详细说明,在疫情期间,您企业遇到的任何困境只要找到艾锑无限,能免费为您提供服务的我们绝不收一分钱,我们全体艾锑人承诺此活动直到中国疫情结束,我们将这次活动称为——春雷行动。
以下还有我们为您提供的一些技术资讯,以便可以帮助您更好的了解相关的IT知识,帮您渡过疫情中办公遇到的困难和挑战,艾锑无限愿和中国中小企业一起共进退,因为我们相信万物同体,能量合一,只要我们一起齐心协力,一定会成功。再一次祝福您和您的企业,战胜疫情,您和您的企业一定行。
微软新作,ImageBERT虽好,千万级数据集才是亮点
继 2018 年谷歌的 BERT 模型获得巨大成功之后,在纯文本之外的任务上也有越来越多的研究人员借鉴了 BERT 的思维,开发出各种语音、视觉、视频融合的 BERT 模型。雷锋网 AI 科技评论曾专门整理并介绍了多篇将BERT应用到视觉/视频领域的重要论文,其中包括最早的VideoBERT以及随后的ViLBERT、VisualBERT、B2T2、Unicoder-VL、LXMERT、VL-BERT等。其中VL-BERT是由来自中科大、微软亚研院的研究者共同提出的一种新型通用视觉-语言预训练模型。继语言BERT之后,视觉BERT隐隐成为一种新的研究趋势。
近期,来自微软的Bing 多媒体团队在arXiv上也同样发表了一篇将BERT应用到视觉中的论文《ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data》
在这篇文章中,作者提出了一种新的视觉语言预训练模型ImageBERT,并从网络上收集了一个大型的弱监督图像-文本数据集LAIT,包含了 10M(1千万)的 Text-Image pairs,这也是目前最大的一个数据集。利用ImageBERT模型和LAIT数据集进行预训练,在MSCOCO和Flicker30k上进行文本到图像、图像到文本的检索任务上获得了不错的结果。
2、背景及相关工作
随着Transformer的提出并广泛应用于跨模态研究,近一年以来,各项任务上获得的结果被推向了一个新的“珠穆朗玛峰”。虽然几乎所有最新的工作都是基于Transformer,但这些工作在不同的方面各有不同。
模型架构的维度:
BERT是面向输入为一个或两个句子的 NLP 任务的预训练模型。为了将 BERT 架构应用于跨模态任务中,现在已有诸多处理不同模态的方法。ViLBERT和LXMERT 先分别应用一个单模态Transformer到图像和句子上,之后再采用跨模态Transformer来结合这两种模态。其他工作如VisualBERT, B2T2,Unicoder-VL, VL-BERT, Unified VLP,UNITER等等,则都是将图像和句子串联为Transformer的单个输入。很难说哪个模型架构更好,因为模型的性能非常依赖于指定的场景。
图像视觉标记维度:
最近几乎所有的相关论文都将目标检测模型应用到图像当中,同时将经检测的感兴趣区(ROIs) 用作图像描述符,就如语言标记一般。与使用预训练的检测模型的其他工作不同,VL-BERT 结合了图像-文本联合嵌入网络来共同训练检测网络,同时也将全局图像特征添加到模型训练中。
可以发现,基于区域的图像特征是非常好的图像描述符,它们形成了一系列可直接输入到 Transformer 中的视觉标记。
预训练数据维度:
与可以利用大量自然语言数据的预训练语言模型不同,视觉-语言任务需要高质量的图像描述,而这些图像描述很难免费获得。Conceptual Captions 是最为广泛应用于图像-文本预训练的数据,有 3 百万个图像描述,相对而言比其他的数据集都要大。UNITER 组合了四个数据集(Conceptual Captions,SBU Captions,Visual Genome, MSCOCO),形成了一个960万的训练语料库,并在多个图像-文本跨模态任务上实现了最佳结果。LXMERT将一些VQA训练数据增添到预训练中,并且在VQA任务上也获得了最佳结果。
我们可以发现,数据的质量和大小对于模型训练而言至关重要,研究者们在设计新的模型时应该对此给予更大的关注。
3、数据集收集
基于语言模型的BERT,可以使用无限的自然语言文本,例如BooksCorpus或Wikipedia;与之不同,跨模态的预训练需要大量且高质量的vision-language对。
目前最新的跨模态预训练模型常用的两个数据集分别是:
The Conceptual Captions (CC) dataset:包含了3百万带有描述的图像,这些图像是从网页的Alt-text HTML属性中获取的;
SBU Captions:包含了1百万用户相关标题的图像。
但这些数据集仍然不够大,不足以对具有数亿参数的模型进行预训练(特别是在将来可能还会有更大的模型)。
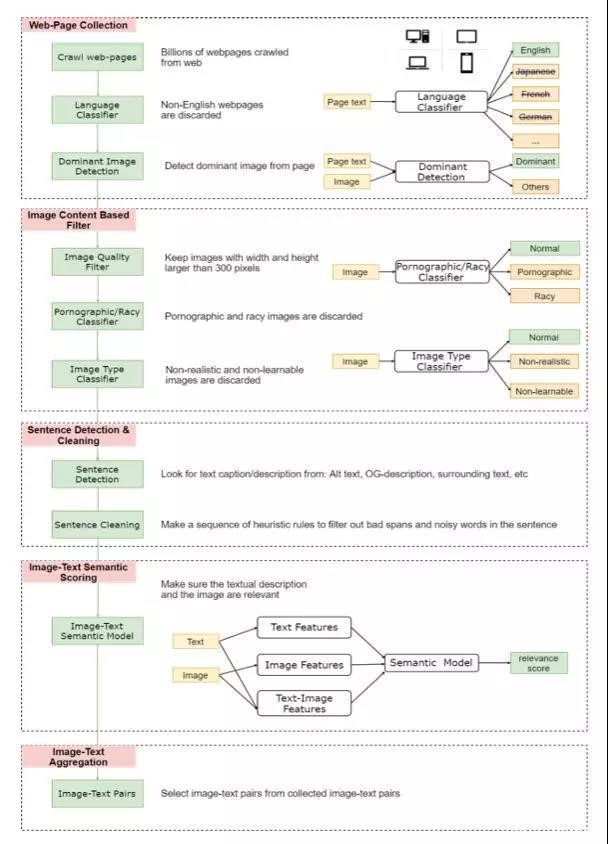
为此,作者设计了一种弱监督的方法(如下图所示),从Web上收集了一个大规模的图像文本数据集。

弱监督数据收集流程
先是从网络上收集数亿的网页,从中清除掉所有非英语的部分,然后从中收集图片的URLs,并利用HTML 标记和DOM树特征检测出主要图片(丢弃非主要图片,因为它们可能与网页无关)。
随后仅保留宽度和高度均大于300像素的图片,并将一些色情或淫秽内容的图片以及一些非自然的图片丢弃。
针对剩下的图片,将HTML中用户定义元数据(例如Alt、Title属性、图片周围文本等)用作图像的文本描述.
为了确保文字和图片在语义上是相关的,作者利用少量image-text监督数据,训练了一个弱image-text语义模型来预测<text, image>在语义上是否相关。用这个模型从十亿规模的image-text 对中过滤掉相关性不高的数据,从而生成的数据集LAIT(Large-scale weAk-supervised Image-Text),其中包含了 一千万张图片,图片描述的平均长度为13个字。

LAIT数据集中的样本
4、ImageBERT模型
如上图所示,ImageBERT模型的总体架构和BERT类似,都采用了Transformer作为最基础的架构。不同之处在于将图像视觉的标记和问题标注作为输入。注意其中图像视觉标记是从Faster-RCNN模型提取的ROL特征。
通过一层嵌入层将文本和图像编码成不同的嵌入,然后将嵌入传送到多层双自我注意Transformer中来学习一个跨模态Transformer,从而对视觉区域和文字标记之间的关系进行建模。
1)嵌入建模
整个嵌入建模分为三个部分:语言嵌入、图像嵌入、序列位置和片段嵌入。
在语言嵌入模块中采用了与BERT相似的词预处理方法。具体而言,是用WordPiece方法将句子分成(标记)n个子词{w0,...,wn-1}。一些特殊的标记,例如CLS和SEP也被增添到标记的文本序列里。每个子词标记的最终嵌入是通过组合其原始单词嵌入、分段嵌入和序列位置嵌入来生成的。
与语言嵌入类似,图像嵌入也是通过类似的过程从视觉输入中产生的。用Faster-RCNN从 o RoIs中提取特征(记为{r0,...ro-1}),从图像中提取特征,从而让这两个特征代表视觉内容。检测到的物体对象不仅可以为语言部分提供整个图像的视觉上下文(visual contexts),还可以通过详细的区域信息与特定的术语相关联。另外,还通过将对象相对于全局图像的位置编码成5维向量来向图像嵌入添加位置嵌入。5维向量表示如下:
其中,(xtl,ytl)以及(xbr,ybr)分别代表边界框的左上角和右下角坐标。5维向量中的第五个分向量相对于整个图像的比例面积。
另外,物体特征和位置嵌入都需要通过语言嵌入投影到同一维度。e(i)代表每个图像的RoI。其计算通过加总对象嵌入、分段嵌入、图像位置嵌入以及序列位置嵌入获得。这意味着每个嵌入被投影到一个向量之中,然后用同样的嵌入大小作为Transformer 隐藏层的尺寸,最后采用正则化层。
在序列位置和片段嵌入中,因为没有检测到Rol的顺序,所以其对所有的视觉标记使用固定的虚拟位置,并且将相应的坐标添加到图像嵌入中。
2)多阶段预训练
不同的数据集来源不同,所以其数据集质量也就不同。为了充分利用不同类型的数据集,作者提出了多阶段预训练框架。如下图所示。
其主要思想是先用大规模域外数据训练预先训练好的模型,然后再用小规模域内数据训练。在多阶段预训练中,为了有顺序地利用不同种类的数据集,可以将几个预训练阶段应用到相同的网络结构。
更为具体的,在ImageBERT模型中使用两阶段的预训练策略。第一个阶段使用LAIT数据集,第二个阶段使用其他公共数据集。注意,两个阶段应使用相同的训练策略。
3)预训练任务
在模型预训练过程中,设计了四个任务来对语言信息和视觉内容以及它们之间的交互进行建模。四个任务分别为:掩码语言建模(Masked Language Modeling)、掩码对象分类(Masked Object Classification)、掩码区域特征回归(Masked Region Feature Regression)、图文匹配(Image-Text Matching)。
掩码语言建模简称MLM,在这个任务中的训练过程与BERT类似。并引入了负对数似然率来进行预测,另外预测还基于文本标记和视觉特征之间的交叉注意。
掩码对象分类简称MOC,是掩码语言建模的扩展。与语言模型类似,其对视觉对象标记进行了掩码建模。并以15%的概率对物体对象进行掩码,在标记清零和保留的概率选择上分别为90%和10%。另外,在此任务中,还增加了一个完全的连通层,采用了交叉熵最小化的优化目标,结合语言特征的上下文,引入负对数似然率来进行预测正确的标签。
掩码区域特征回归简称MRFR,与掩码对象分类类似,其也对视觉内容建模,但它在对象特征预测方面做得更精确。顾名思义,该任务目的在于对每个掩码对象的嵌入特征进行回归。在输出特征向量上添加一个完全连通的图层,并将其投影到与汇集的输入RoI对象特征相同的维度,然后应用L2损失函数来进行回归。
值得注意的是,上述三个任务都使用条件掩码,这意味着当输入图像和文本相关时,只计算所有掩码损失。
在图文匹配任务中,其主要目标是学习图文对齐(image-text alignment)。具体而言对于每个训练样本对每个图像随机抽取负句(negative sentences),对每个句子随机抽取负图像(negative images),生成负训练数据。在这个任务中,其用二元分类损失进行优化。
4)微调任务
经过预训练,可以得到一个“训练有素”的语言联合表征模型,接下来需要对图文检索任务模型进行微调和评估,因此本任务包含图像检索和文本检索两个子任务。图像检索目的是给定输入字幕句能够检索正确的图像,而图像文本检索正好相反。经过两个阶段的预训练后,在MSCoCO和Flickr30k数据集上对模型进行了微调,在微调过程中,输入序列的格式与预训练时的格式相同,但对象或单词上没有任何掩码。另外,针对不同的负采样方法提出了两个微调目标:图像到文本和文本到图像。
为了使得提高模型效果,还对三种不同的损失函数进行了实验,这三种损失函数分别为:二元分类损失、多任务分类损失、三元组损失(Triplet loss)。关于这三种微调损失的组合研究,实验部分将做介绍。
5、实验
针对图像-文本检索任务,作者给出了零样本结果来评估预训练模型的质量和经过进一步微调后的结果。下面是在 MSCOCO 和Flickr30k 数据集的不同设置下,对ImageBERT模型和图像检测和文本检索任务上其他最先进的方法进行的比较。
1)评估预训练模型
如前面所提到,模型经过了两次预训练。首先是在 LAIT 数据集上,采用从基于BERT 的模型初始化的参数对模型进行了预训练;然后又在公开数据集(Conceptual Captions, SBU Captions)上对模型进行二次预训练。具体过程和实验设置请参考论文。
在没有微调的情况下,作者在Flickr30k和MSCOCO测试集上对预训练模型进行了评估,如下:
零样本结果如表 1 所示,我们可以发现,ImageBERT预训练模型在MSCOCO 获得了新的最佳结果,但在Flickr30k数据集上却比 UNITER模型的表现稍差。
在微调后,ImageBERT模型获得了有竞争力的结果,相关情况在表2 部分进行说明。值得一提的是,相比于其他仅有一个预训练阶段的方法,这种多阶段的预训练策略在预训练期间学到了更多有用的知识,因而能够有助于下游任务的微调阶段。
2)评估微调模型
在检索任务上微调后的最终结果如表2 所示。我们可以看到,ImageBERT模型在Flickr30k 和 MSCOCO(同时在 1k和 5k的测试集)上都实现了最佳表现,并且超越了所有的其他方法,从而证明了本文所提的面向跨模态联合学习的 LAIT 数据和多阶段预训练策略的有效性。
3)消融实验
作者也在 Flickr3k 数据集上对预训练数据集的不同组合、全局视觉特征的显示、不同的训练任务等进行了消融实验,以进一步研究ImageBERT模型的架构和训练策略。
预训练数据集
作者使用不同数据集的组合来进行预训练实验。结果如表3所示。CC表示的仅在 Conceptual Captions 数据集上进行预训练;SBU 表示仅在 SBU Captions数据集上进行预训练;LAIT+CC+SBU表示使用LAIT, Conceptual Caption 和 SBU Captions的组合数据集进行预训练;LAIT → CC+SBU 表示使用 LAIT 来完成第一阶段的预训练,之后使用 Conceptual Captions和SBU Captions 数据集来做第二阶段的预训练。
可以看到,用多阶段的方法来使用三种不同的域外数据集,获得了比其他方法明显更好的结果。
全局图像特征
值得注意的是,检测的ROIs可能并不包含整个图像的所有信息。因此,作者也尝试将全局图像特征添加到视觉部分。文章使用了三个不同的CNN 模型(DenseNet,Resnet, GoogleNet)从输入图像上提取全局视觉特征,然而却发现并非所有的指标都会提高。结果如表4的第1部分所示。
预训练损失
作者也将由UNITER引起的MRFR损失添加到预训练中,结果在零样本结果上获得略微提高,结果如表4 的第2 部分所示。这意味着增加一个更难的任务来更好地对视觉内容进行建模,有助于视觉文本联合学习。
图像中的目标数量 (RoIs)
为了理解ImageBERT模型的视觉部分的重要性,作者基于不同的目标数量进行了实验。如表4的第4部分所示,ImageBERT模型在目标最少(目标数量与ViLBERT一样)的情况下,在检索任务上并没有获得更好的结果。
可以得出结论,更多的目标确实能够帮助模型实现更好的结果,因为更多的 RoIs 有助于理解图像内容。
微调损失
针对在第4部分所提到的三项损失,作者尝试在微调期间进行不同的组合。如表4的第4 部分所示,模型通过使用二元交叉熵损失(Binary Cross-Entropy Loss),本身就能在图像-文本检索任务上获得最佳的微调结果
相关文章



 关闭
关闭