
艾锑知识 | 数据库高可用HA技术简介
2020-02-19 15:00 作者:艾锑无限 浏览量:
疫情即将结束,如何提升企业工作效率
艾锑无限免费为企业提供IT服务
这几天如果大家关注疫情数据的变化,可以看到新增确诊病例在持续下降,这意味着疫情很快就会结束,大家再也不用在家办公了,到不是在家工作有什么不好,但人类发明工作不简简单单只是为了实现结果的达成,还有一个非常重要的因素就是人与人之间的联结,这是人类内在价值的需求,透过 工作与人接触,共同感受彼此的能量流动,从而达到自我价值的实现,这就像演员都渴望登上奥斯卡的舞台,来实现自我角色的认可一样。

在家办公,毕竟是家,松、散、懒以及无所谓的态度会随时产生,我相信不是每个人都会这样,但大部分人会如此,因为家本来就是放松的能量场,接下来大家即将回到公司,回到自己的工作岗位,难免会把在家的状态带入工作中,如果每个人都是这样的状态,企业很快会陷入新的窘境,所以没有 状态,也不会有好的结果,状态就是一切。
团队的势气决定企业整体的战斗力,那如何调整陆陆续续回来的团队成员呢?

艾锑无限对中小企业有三条建议:
第一,重新梳理整个企业的战略,疫情的发生,是否给你企业带来了变化?如果有那是什么?是否需要调整自己原有的战略方向来应对疫情发生后的影响?
第二,重新明确每个人的目标和目的,目标就是重回企业的人要干什么?干到什么程度?什么时间可以看到这个结果的发生?目的就是为什么要实现这个目标?这个目标与自己的意义是什么?与企业的意义又是什么?达成了会怎么样?达不成又会怎么样?
只有清晰这些问题,才会让回到工作岗位的人快速改变自己的状态投入到接下来的工作中,只有积极的状态投入工作才会有积极的成果发生,反之依然。
第三,企业高管与员工建立一对一的对话机制,因疫情的影响,每个人心理或多或少都会产生一些内在的变化,作为企业的高层管理人员,最好与企业内部员工一对一的进行沟通,去了解在这个过程中员工受到的影响和产生的变化,以便接下来更好的调整他们的状态,因为如果他们的心没有回来,
企业的要求和制度带来的也都是大家没有能量的重复和机械的工作,最终也很难带来好的结果。
以上三点是企业管理者需要重视的,当然身为企业的一员无论是谁也都需要重新审视自己的状态,因为这关系着企业接下来的生、死、存、亡,能量是企业持续发展的源泉,以上所有的目的都是为了聚合企业人的能量,重新点燃大家面对工作的激情和信心,这将是企业至胜的法定。
当然这只是我们一家之言,每家企业可根据自身的情况做出相应的调整和改变。
以上三点做为每一家企业的管理者都有必要重视起来,因为这关系着企业接下来的生、死、存、亡,当然这只是我们一家之言,可根据自身的情况做出相应的调整和改变。
那为什么我们会有这样的思考,因为艾锑无限是一家企业互联网”云”解决方案服务平台,企业在初创时经历了2003年的非典,后来又经历了2008年的经济危机以及2016年互联网创业大潮,生生死死,几经沉浮,最终发现上述三点是生死线中最重要的,所以愿意分享给大家,期望这次疫情大家不仅
能渡过难关,更能看见大家在这个过程中强而有力的领导力,让自己企业力挽狂澜,让自己的工作更上一层楼,让自己的生活在2020年更精彩。
在这次疫情后各个企业恢复的过程中,艾锑无限还能为大家做的就是免费为中小企业提供相应的IT服务,以下是艾锑无限可以提供服务的内容,如果大家有相应的需求,可以打下面的电话与我们的企业相关人员联系,我们一定会尽全力帮助大家渡过难关。

历经10几年,艾锑无限服务了5000多家中小企业并保障了几十万台设备的正常运转,积累了丰富的企业IT紧急问题和特殊故障的解决方案,我们为您的企业提供的IT服务分为三大版块:
第一版块是保障性IT外包服务:如电脑设备运维,办公设备运维,网络设备运维,服务器运维等综合性企业IT设备运维服务。
第二版块是功能性互联网外包服务:如网站开发外包,小程序开发外包,APP开发外包,电商平台开发外包,业务系统的开发外包和后期的运维外包服务。
第三版块是增值性云服务外包:如企业邮箱上云,企业网站上云,企业存储上云,企业APP小程序上云,企业业务系统上云,阿里云产品等后续的云运维外包服务。
更多服务也可以登录艾锑无限的官网: www.bjitwx.com 查看详细说明。
每家企业都有着不同的人,每个人都有着不一样的思考,所以企业不需要统一所有人的思维,企业只需要统一所有人的心,因为只要心在一起了,能量就会合一,能量合一企业将无所不能。
相信这次疫情带给中国企业的不仅仅是灾难,更有可能的是历练,这几年经济发展如此快速,大部分中小企业的成长都是随着国家政策及整个社会的大势起来的,没有经过太多的挑战和困难,所以存活周期也会很短,从2016年大众创业,万众创新倡导下成立了上千万家企业,但真正存活下来的就
只有几万家,这样的结果即不能给国家带来稳定持续发展的动力,也不能为社会创造更大的价值,反而让更多的人投机取巧,心浮气躁,沉不下来真正把一件事做好,做到极致。
所以这次疫情也会让大部分企业重新思考,问问自己,为什么要创立这家企业,想为这个国家和社会带来的是什么?企业真正在创造的是什么?如何做才能让社会因自己的企业变得更好?.....
当企业真正去思考,用心去创造价值的时候,也就是人们幸福快乐的时候,因为再也不用担心假货、次货、买到不好的产品,更不用担心环境被污染,大气被破坏,疫情即是一场灾难,又是重新成就中国企业的一次机会,让全世界人觉醒,生命只有一次,我们要如何做才能不枉此生呢?

你对世界微笑,世界绝不会对你哭,希望大家都能积极乐观起来,让自己、自己的家人、自己的企业、还有自己的国家都快乐起来,把焦点、意识、能量放在我们想要什么上,而不是不要的事情上,我相信,就在不久的将来,我们一定会看到一个富强、文明、健康的中国以及一个和谐友爱的世界。
万物同体,能量合一,最后无论你是中小企业,还是大型国有企业,只要你选择艾锑无限,我们就一定全力以赴帮助大家渡过难关,服务有限,信息无限,透过全体艾锑人的努力,为您收集最有效的IT技术信息,让您企业更快速解决遇到的IT问题:
艾锑知识 | 数据库高可用HA技术简介
数据库高可用是一个复杂的系统工程,本文主要介绍了几种数据库高可用的基本技术: HADR、 HACMP、 数据复制,存储层容灾和DPF高可用。并结合实践实际,分别论述了它们的适用场景和技术特征。在不同场景,不同的业务连续性级别下,我们可以组合使用这几种技术,以实现从存储,网络,系统,数据库到应用的高可用技术。
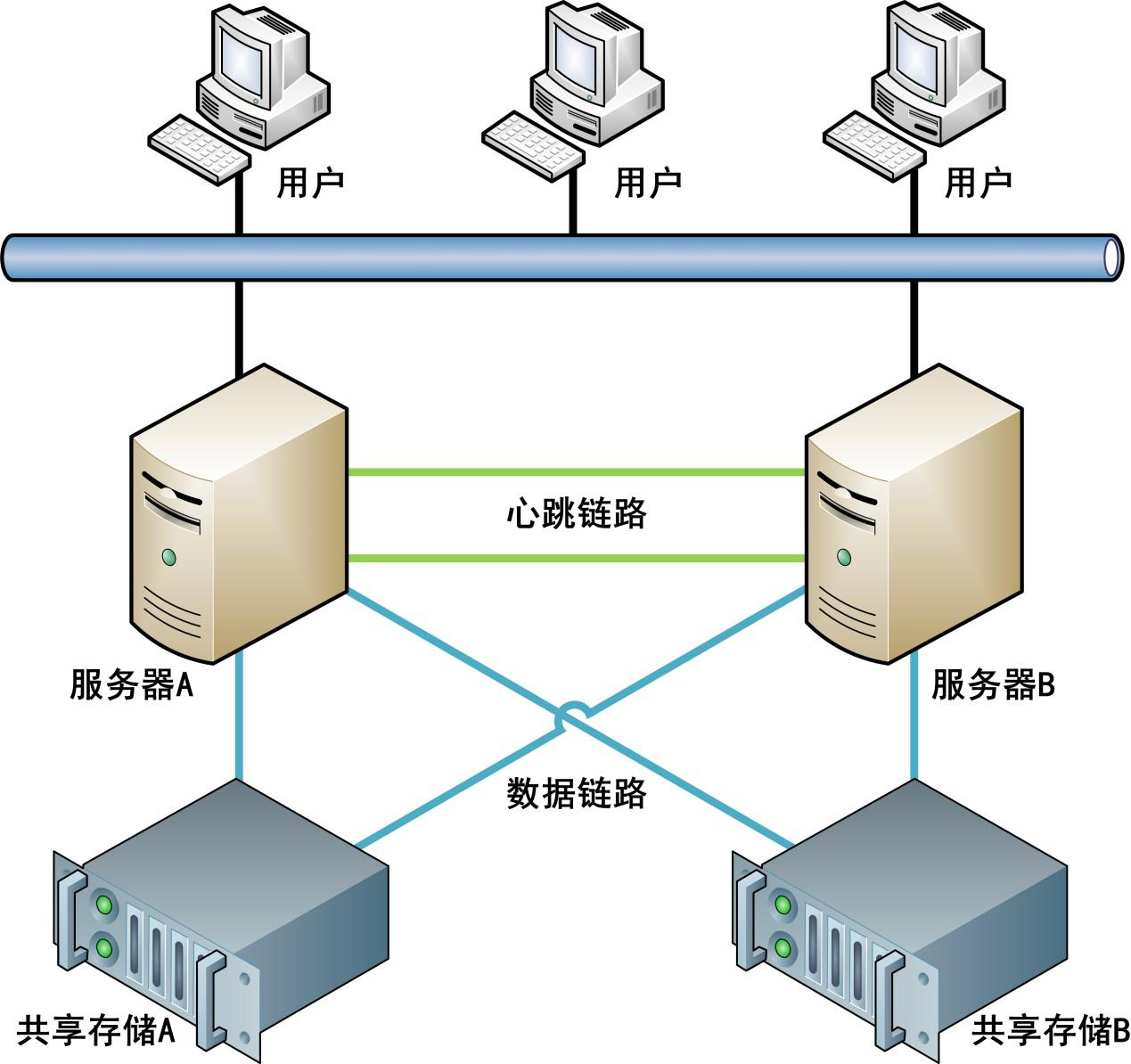
一. DB2 HADR
HADR全称为High Availability Disaster Recovery ,是IBM DB2数据库上的数据库级别的高可用性数据复制机制,最初被应用于Informix数据库系统中,称为High Availability Data Replication(HDR),IBM收购Informix之后,这项技术就应用到了新的DB2发行版中。HADR有一主一备数据库,在9.7之前备机不可读,9.7之后备机可读可以降低主数据库的负担。(这个Oracle的DataGuard逻辑备机可读做的就很好,但是为什么IBM会落后呢?),在数据专线带宽足且稳定的情况下,在要求主备完全数据无损的时候,推荐用同步方式传送,或者能容忍一定少量的损失,可以用准同步,但是推荐在在生产中心和同城的灾备中心之间(LAN或者MAN),如果在1000公里以上带宽和时延都没什么保障的话,比如北京和上海,最好还是用异步的方式,如果更差或者对OLTP的实时性要求较高还可以用超级异步,当然这对流水的损失要有一定的容忍度。
HADR一个很不好的特点是不能用于DPF,只能适合单分区数据库,这就限制了数据库在高可用下的规模以及并发性。HADR从一些实际应用来看,切换速度要比DG要快,而且切换出现故障的可能性要小些。
谈到HADR绝对不能离开DataGuard,实际上中国人民银行对两地三中心的规定就非常适合DataGuard的两个备用数据库的方式,生产中心用主数据库,同城灾备中心用物理备用,异地灾备中心用逻辑备用。Oracle的DataGuard在网络故障恢复之后可以自动同步。
HADR有一个弱点就是不能进行数据压缩和加密,如果没有VPN就麻烦了,但是HADR可以集成第三方的SSH软件。而DG本身就集成了SSH进行压缩和加密功能。HADR最要命的是不能支持异构数据库的复制,当然这个也不是他的主要场景。
DB2异地灾备用HADR的比较多,在9.7之前用HADR的话备机不可读很麻烦,所以有的时候就要用Q复制,这样主备都可读,如果要零容忍和短切换时间的话,用HADR比较靠谱。
二. SQL复制和Q复制
SQL复制主要应用于相同局域网内。Q复制远程好一点,因为在网络比较差的时候,WebSphere MQ可以缓存一段时间数据。Q复制一般结合HADR比较多,用于实现数据远程异地复制(比如中国烟草总公司容灾中心)。Q复制可以通过分析事务日志来获取系统变化,对系统的性能影响比较小。是高效率的复制方案。但是Q复制只是对DB2支持的比较好,对Oracle嘛就那样,其他的数据库支持的都不好。Q复制也支持表级别的复制。Inforsphere CDC(原来叫Data Mirror)支持多种数据库的表复制。
Oracle也有GoldenGate,这个熟悉的人也知道,支持ORACLE最好,其他的嘛不好说。但是CDC在表依赖上有些复杂,会有点问题,需要具体处理。
三、 HACMP
HACMP Cascading模式中,有主又备,节点有优先级,资源组在优先级搞的节点运行,高优先级节点故障恢复之后,资源组重新归位。Cascading用于主备机硬件性能有较大差别的环境,节约成本,这个对于不差钱的运营商、航空、银行、政府绝对不会采用。Rotating模式中,有主有备,节点优先级相同,资源组在先启动节点运行,节点故障恢复后,资源组不会前移。Rotating适用于对可用性要求较高的场景,电信行业的数据业务,增值业务,彩铃等产品多采用这种方式。
Concurrent模式无主备,节点优先级同,资源组在所有节点运行,节点故障不会导致资源组切换,故障节点恢复后,资源组恢复可用,不发生前移,适合大容量据点。Concurrent模式一般和Oracle的RAC或者并行服务器(OPS)合用较多。
电信业务中,增值特服大容量据点采用,智能网、BOSS也有应用,这种模式的结合和PureScale十分类似。但是HACMP中数据库只有一份,如果数据库被破坏,主机和操作系统还好也没毛用,所以还要结合HADR才更安全。HACMP一般是由网卡和机器Down机所触发的,软件改动不知道是否能够触发呢?我也不是很清楚。
其实HADR,HACMP在本地数据中心的效果最好,如果是异地的话最好是使用HAGEO,或者在存储层的做,因为软件层面效率并不是很高而且还很占主机的系统资源和网络带宽,当然不同公司的选择和考虑是不一样的。
四、DPF的高可用方案
关于DPF,其实DPF本身并没有高可用性的方案。但是由于多节点技术,在某些条件满足的情况下有一定程度上的容灾。要求Catalog节点不能Down,如果非关键节点Down,DPF数据库还是可以访问的。
但是如果你要某些表可访问,只有在该表所在表空间所覆盖的分区节点没有Down。DPF节点Down有几种情况,如果是操作系统或者网络故障,可以通过HACMP恢复,如果是节点数据库损坏,就没有办法了。其实DPF这么多节点也是引入了故障点的概率,所以OLTP在没有HA保障的话,是不敢建在DPF上的。
DPF在建库的时候,最好规划好关键节点的HA和备份工作,定期检查表,表空间的分布,并记录下来,有问题可以迅速定位和恢复。表空间级别的备份在DPF还是很重要的。
如果资金保障比较充足的话,建议给所有几点都做HA,因为一般数据库本身导致的可用性问题要比OS和硬件网络导致的要少很多。DPF跨节点表和表空间特别多,千万不要因为节点本身的问题造成表空间不可用那个。
五、存储层的容灾
谈到高可用,不能离开存储层的容灾,比如磁盘镜像技术,和第三方的备份技术。当然,Everyone都知道,存储层的技术避免不了宕机的,要有一段切换时间。
SRDF一种比较复杂技术。SRDF在国外应用的非常多,国内银行也开始应用。SRDF可以实现分层的数据备份和恢复。可以跨大楼,可以实现全球的数据复制。同样的,和HADR和DG类似,也有同步,准同步和异步的模式。覆盖的距离可以多达几千公里,但是因为无需考虑类似于HADR的实时性交易问题,另外SRDF支持所有的主机和数据库系统。这个一般在数据中心搬迁的时候用的比较多。
如果在距离比较近的时候比如数公里的距离,可以使用裸光纤,如果较远的话,就要用华为或者Cisco的DWDM进行光纤延伸,根据数据传输的需求制定线路的速率。SRDF非常昂贵,如果我们的数据和客户交易不强相关的话,就可以使用笨笨的磁带拷贝搬迁方法,建立应用系统,然后再用SRDF传输实时要求高的数据,启动新数据中心的系统,切换网络。
Veritas大家也非常了解了,论坛上用过的人该很多。通过 Veritas的BMR技术,可以直接连操作系统带数据全部备份到数据中心。更为强悍的是,无需LAN的SAN多磁盘并发备份,减少对网络带宽的影响。通过BMR可以制作启动光盘,进行系统恢复。针对于不同的数据库还提供相应的agent,提供在线热备份技术。
六、高可用的网络、电力和制度方面
网络就不用说了,网卡漂移,多子网,冗余光纤等。一般来说,生产中心和灾备中心之间要有四个交换机,以及四个存储层主机实现高可用,并配备多路光纤。 电力的话,要有UPS备用电源和发电机。数据中心的电力和网络一定要求运营商提供第一流的保障级别,否则谁都付不起责任。当然还有自来水、便利的交通等等方面。
大规模的电信运营商、银行都有非常成熟的制度和流程。中国人民银行也有非常详尽的规范。各银行也制定自己的一些细节规定。制度一定要控制滥用权限、各种误操作、以及指明应急时候的操作。前面的兄弟也有一些阐述,比如双保险,及时进行灾备切换演练,整体级别的,应用软件级别的都要有。数据中心建成的时候,要各种切换和场景都要尝试。
相关文章



 关闭
关闭