
IT运维知识:Exchange 2010 DAG 跨站点转移
2020-03-21 09:16 作者:艾锑无限 浏览量:
云计算提供商的网络性能有哪些不同
每个云计算提供商的网络连接方式各不相同,这会导致网络性能和可预测性方面的地理差异。随着越来越多的企业考虑将业务迁移到云平台,尤其是软件定义广域网(SD-WAN)和多云,了解每个公共云服务提供商提供的服务以及如何进行比较至关重要。
2019年的研究提供了一个更全面的视角,在其研究名单上又增加了两个云计算提供商:阿云和IBM云。研究报告比较了2018年和2019年的调查数据,显示了每年发生的变化以及引发这些变化的原因。
ThousandEyes公司在四周的时间内,定期从使用这五个公共云提供商的全球数据中心的98个用户位置收集双向网络性能指标,例如网络延迟、数据包丢失以及抖动。此外,还研究了美国领先的宽带互联网服务提供商(ISP)的网络性能,其中包括AT&T、Verizon、Comcast、CenturyLink、Cox和Charter。
然后,该公司分析了超过3.2亿个数据点,以创建评估基准。
提供商之间的网络服务并不一致
ThousandEyes公司在最初的研究中发现,一些云计算提供商十分依赖公共互联网来承载用户流量,而其他云计算提供商则不是这样。在2019年的研究中,云计算提供商在双向网络延迟方面总体上表现出相似的性能。
但是,ThousandEyes公司发现网络架构和连接性差异对流量在用户与某些云计算托管区域之间的传输方式有着很大影响。AWS和阿里巴巴主要依靠全球互联网来传输用户流量。微软Azure和谷歌云平台使用其专用骨干网。IBM公司与其他公司不同,采用二者混合的方法。
ThousandEyes公司检验了AWS Global Accelerator是否优于全球互联网的理论。AWS Global Accelerator于2018年11月推出,该服务采用的不是默认的全球互联网,而提供使用AWS专用骨干网,并向用户收费。尽管其在全球某些地区的网络性能确实有所提高,但在其他情况下,全球互联网比AWS Global Accelerator更快、更可靠。
即使在成熟的美国市场,企业用来连接每一个云计算提供商的宽带网络服务提供商(ISP)的服务也并不一致。在对6个美国网络服务提供商(ISP)的网络性能进行评估后,记录了次优的路由结果,在某些情况下,其网络延迟是预期的10倍。
地点至关重要
云计算提供商的服务在穿越一些国家的过滤防火墙时,通常都会遇到丢包的情况。该公司在2019年的研究中,仔细检查了云计算服务提供商在一些国家的运营费用,这对在线企业而言是极具挑战性的地理位置。
在世界其他地区,拉丁美洲和亚洲表现出所有云计算提供商最大的性能差异。例如,由于反向路径不太理想,谷歌云平台的托管区域从里约热内卢到圣保罗的网络延迟是其他五家云计算提供商的六倍。但是在北美和西欧,所有五家云计算提供商均展现了强大网络性能。
这项研究的结果证明,地点是主要因素,因此,企业在选择公共云提供商时应考虑用户到主机区域的性能数据。
多云连接
在2018年的研究中,ThousandEyes公司发现AWS、谷歌云平台、Azure的骨干网络之间的广泛连接。在2019年的研究中还有一个有趣的发现,在将IBM公司和阿里云添加到调查列表中时,多云连接变得不稳定。
ThousandEyes公司发现IBM公司和阿里云尚未与其他提供商完全建立直接连接。那是因为他们通常使用网络服务提供商(ISP)将其云平台连接到其他提供商。另一方面,AWS、Azure和谷歌云平台可以直接相互对等连接,并且不需要第三方网络服务提供商(ISP)的服务进行多云通信。
随着多云计划的兴起,在评估多云连接性时,应将网络性能作为一项衡量标准,因为它似乎在云计算提供商和地理边界之间不一致。
ThousandEyes公司的综合性能基准可以作为企业确定哪个公共云提供商最能满足其需求的指南。但还是需要谨慎,选择公共云连接的用户应该考虑全球互联网的不可预测性、如何影响性能、面临的风险,以及运营复杂性。用户应通过个案收集自己的网络情报来应对这些挑战。只有这样,他们才能从云计算提供商所提供的内容中充分受益
IT运维知识:Exchange 2010 DAG 跨站点转移
Exchange Server 2010在跨站点部署数据库可用性组(Database Availability Group, DAG)时,需要考虑站点间的转移问题。即:一个站点的Exchange服务器宕机时,另一个站点的Exchange能否自动切换,并保证客户端访问的不间断。事实上,跨站点的转移有两种,一种是故障转移Fail over,另一种是切换Switch over。故障转移是服务器自动进行的一种行为;而切换则需要管理员的人工干预才能够完成。
在理想状态下,总是希望实现Failover,因为Failover是不需要任何人工干预而自动进行的,Failover可以最大限度地保证服务的可用性。
Exchange组织拓扑
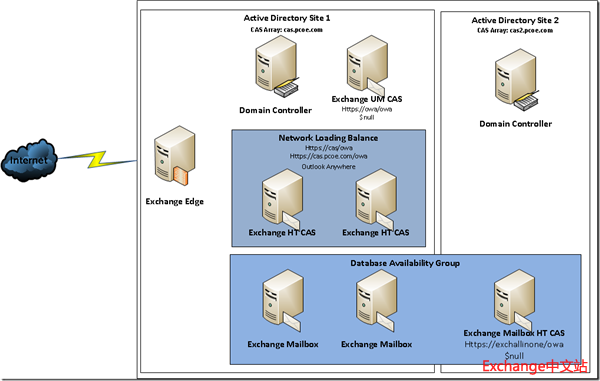
组织中配置了3个数据库,每个数据库有3个副本,分别位于加入DAG的3台Exchange Server 2010邮箱服务器上。
各活动目录站点中配置的Client Access Array。


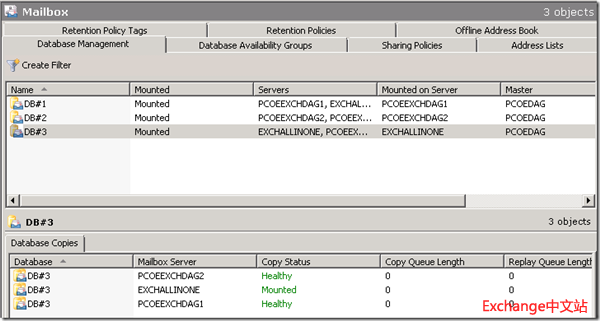
由于Exchange Server 2010的客户端访问是按照活动目录站点进行划分的,而为了节省站点间的网路带宽,管理员应该尽可能使用户访问Exchange邮箱时,使用其所登录站点的Exchange服务器。例如这里的配置,DB#3上存放的是2ndSite内的用户邮箱,默认会在ExchAllinOne上被激活,而DB#3上的RPCClientAccessServer设置为2ndSite上的Client Access Array,这样就可以保证,在正常情况下,2ndSite的用户只需要连接到ExchAllinOne就能完成邮箱访问,而不需要使用1stSite内的Exchange服务器。
DAG的配置

Client Access Server上虚拟目录的配置情况,以OWA为例,其它虚拟目录如OAB/ECP等服务,它们与OWA所使用的主机名完全相同:

服务器上启用了Outlook Anywhere。
客户端连接
对于一个邮箱位于DB#3上的用户,通过AutoDiscover获取的默认Outlook配置如下:
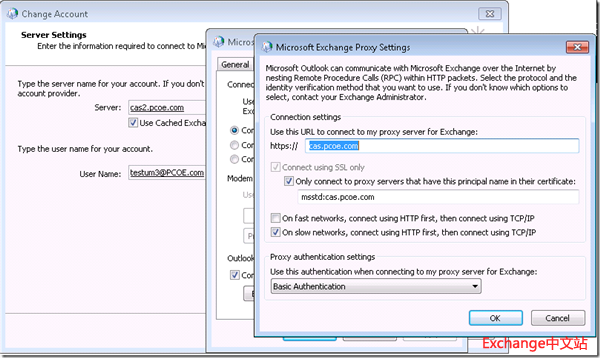
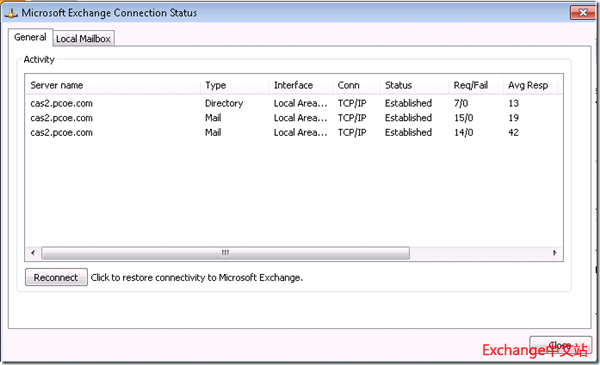
关闭ExchAllinone,数据库DB#3切换到1stSite的PCOEExchDAG2上。
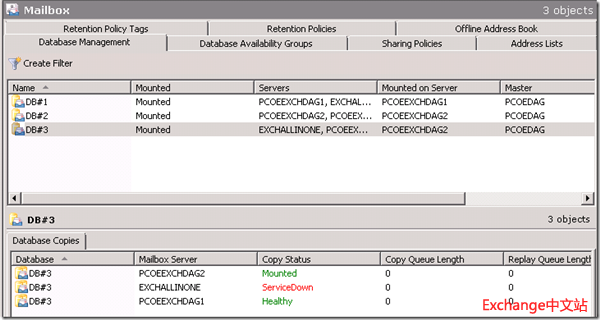
答案是:这类用户将无法继续使用MAPI方式进行连接了。
对客户端的影响
Outlook客户端重新发起连接,使用Outlook Anywhere方式进行。
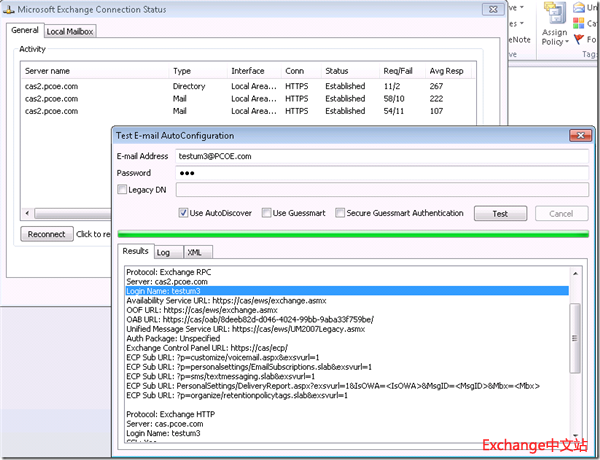
如果2ndSite也是Internet-Facing的,就只能采用Switchover方式,由管理员手动干预才能够恢复客户端的访问了。
相关文章



 关闭
关闭